IntegrationDatabase or integration via database is a pattern best avoided. It is a pattern where multiple applications or services integrate via the database. In an extreme but unfortunately not so uncommon case, multiple applications share a table in the same database.
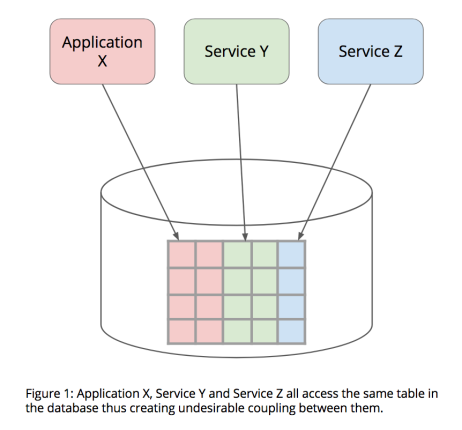
In this post, I would like to talk about the various types of coupling created when multiple applications integrate via the same database. It is highly encouraged that a service or application owns its data. When a service owns its data, it creates explicit contracts through APIs that are business-truthful as opposed to implicit contracts via database tables that are more implementation detail.
Here are the various types of coupling.
- Schema coupling. The shared database schema has to accommodate the needs of all the applications accessing the database. This means getting buy-in from all the consumers when changing database schema. A particular result of schema coupling is when you end up with sparse tables, where certain columns are only used by an application or a subset of the applications. This adds to the cognitive load of the team building applications that are not using those columns.
- Data coupling. The data semantics in the tables also have to aligned across all the different applications. This can get quite hairy over time since the data semantics are part embedded in the database and part in the applications. Very often, I have seen states of a process being stored in the database like “Started”, “Processing”, “Finished” and being interpreted differently by different applications. It becomes very hard to change these states as they create a ripple effect across all the applications using it. It also can be tricky to add new states.
- Abstraction coupling. When systems from outside the domain access the database tables of an application, it creates an abstraction coupling where the abstraction the external systems are coupled to is more of an implementation detail rather than a business-truthful abstraction. For example, when customers are exposed the “raw” inventory from the database for a given store when what they really want is “available to sell” inventory for the store. Available to sell inventory factors in store demand, lost inventory, damaged inventory, et al. When exposing the raw inventory, the customers then have to access other tables or build other logic to get to the available to sell inventory. Thus, exposing a business-truthful abstraction as a service such as available to sell inventory hides the inventory complexity inside the service and provides a way for the service to evolve the implementation over time. Also, thinking about a system interface in a business-truthful way, makes the system more widely understood and reduces cognitive load for developers consuming the abstraction. Hence, it is best to separate the system interface from the underlying implementation.
- Deployment coupling. As a direct result of schema and data coupling, database changes have to be coordinated with all the systems accessing the database. Database is an implementation detail of the system. Changing the database should not require any release coordination with its consumers as long as the system interface has not been changed.
- Runtime coupling. When multiple applications access the same database it is hard to scale or performance test those applications in isolation. To replicate “production load” for an application, you would have to create activity in all the applications hitting the database to truly understand the deadlocks/race conditions in that application. In essence, it becomes very hard to commit to SLAs for an application as there is very little isolation between the traffic coming from different applications.
Thanks for reading! Comments/feedback welcome.